import torch
import torch.nn as nnHere I have implemented the transformer architecture from scratch with a focus on forward pass. This will help understand how the inputs flow through each module. Note that backpropagation code is not implemented.
![]()
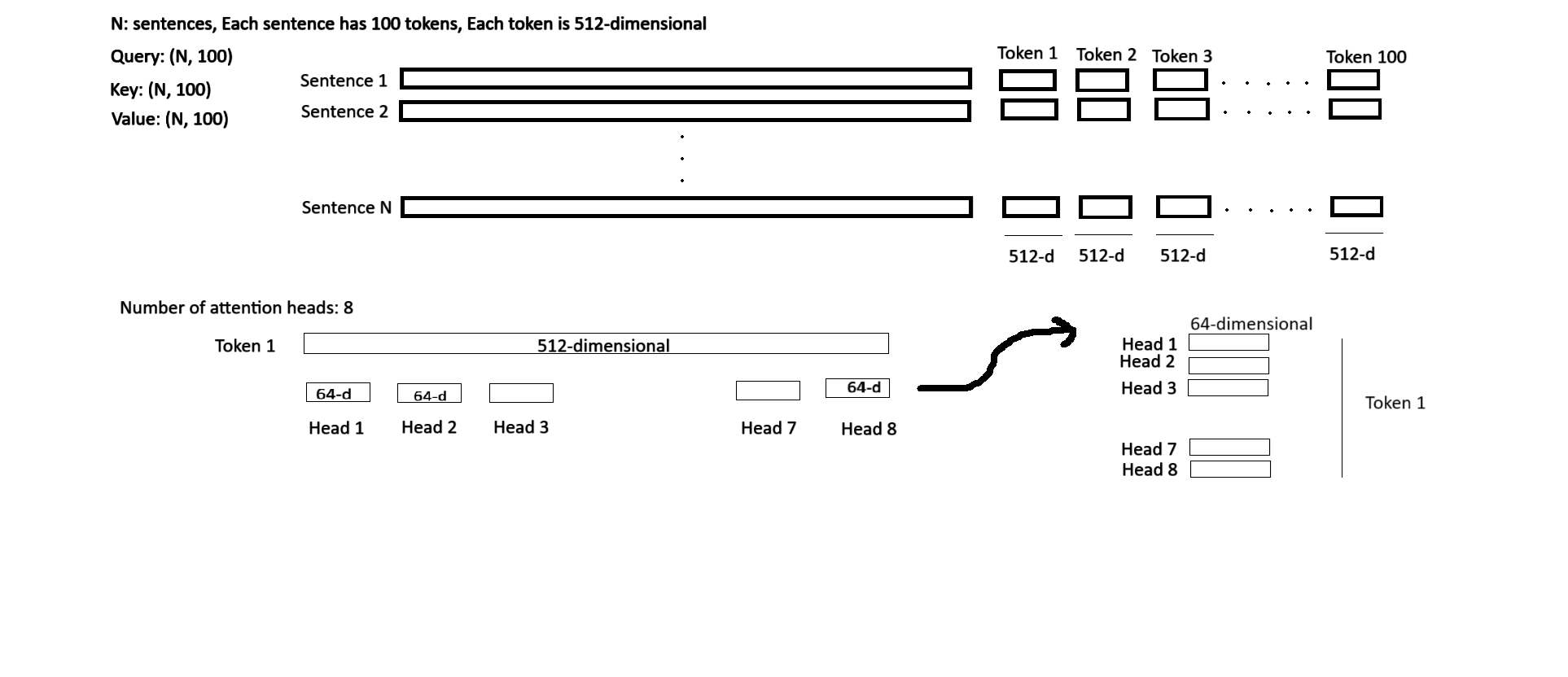
Here we are building multi head attention according to transformer paper 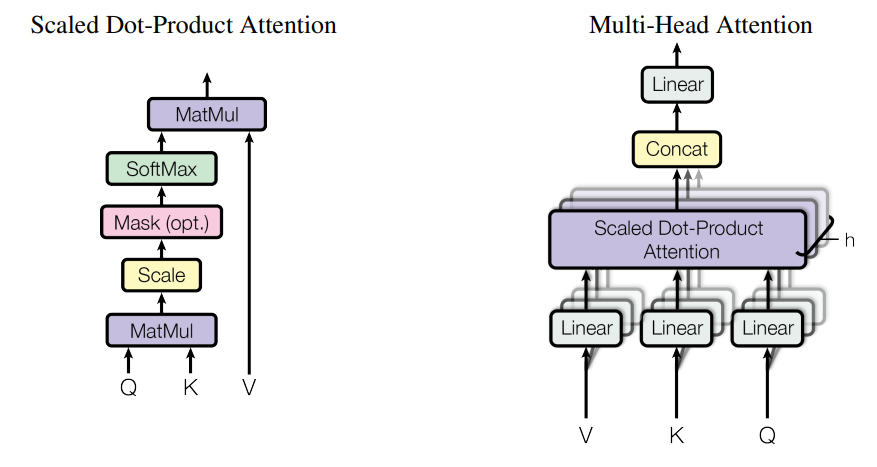
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads): # why are we dividing the embed_size among heads
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
self.W_k = nn.Linear(self.embed_size, self.embed_size) # every time the input to the query, key and value matrix will be a vector of dimension embed_size and it will brought down to head_dim
self.W_q = nn.Linear(self.embed_size, self.embed_size)
self.W_v = nn.Linear(self.embed_size, self.embed_size)
self.fc = nn.Linear(self.heads*self.head_dim, self.embed_size)
# The query, key and value have tokens and each token is of size embed_size.
# Suppose, there are 100 tokens in a query, each token is 512-dimensional.
# The embed_size is divided among heads. Suppose the number of heads is 8.
# The 512-dimensional token is divided among heads. Each head has 64-dimensional query
# One query has 100 tokens
# One token is 512-dimensional. Embed size is 512-dimensional.
# Each head has 64-dimensional token.
# (N, 100, 512) is the input taken by Linear layer W_q and then the output is reshaped into (N, 100, 8, 64)
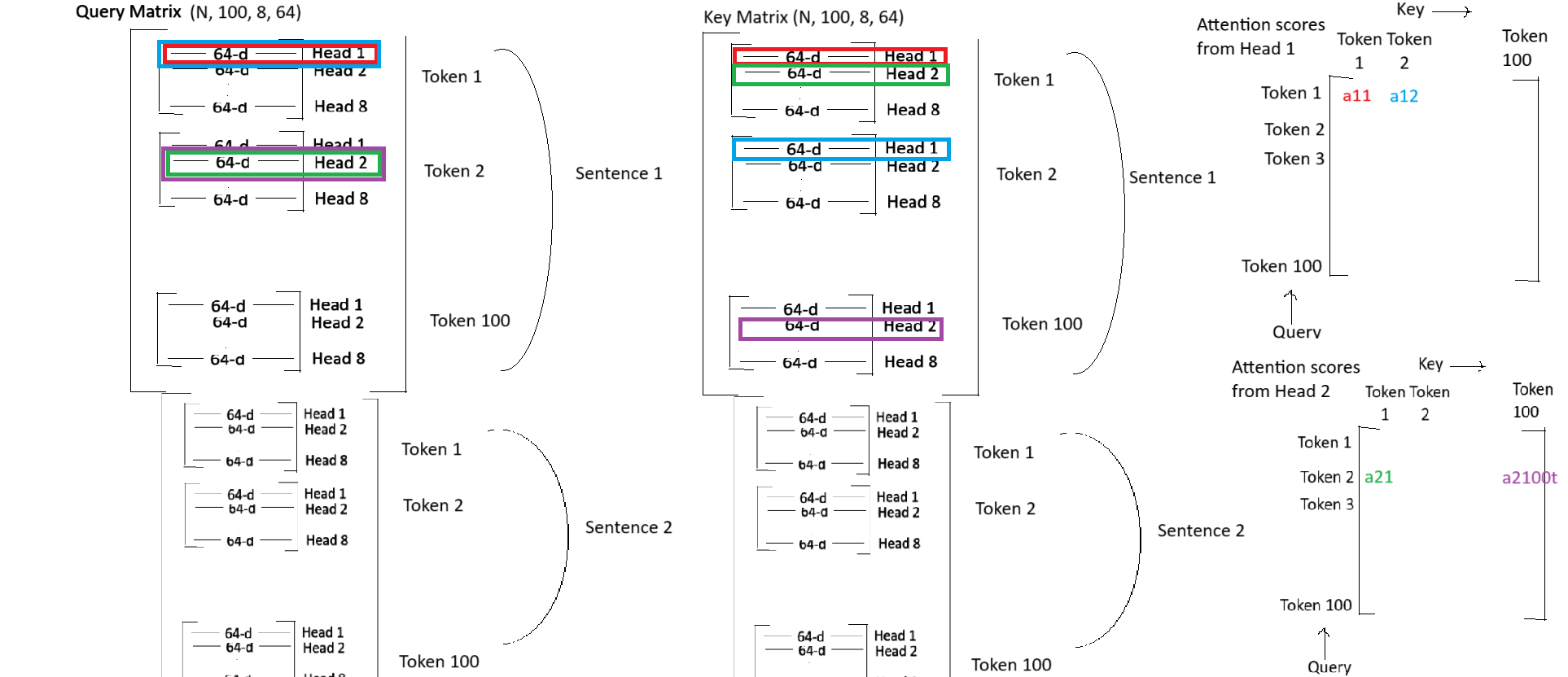
def forward(self, query, key, value, mask):
N = query.shape[0]
query_len, key_len, value_len = query.shape[1], key.shape[1], value.shape[1] # here we find out how many tokens are present in query, key and value
query = self.W_q(query)
key = self.W_k(key)
value = self.W_v(value)
# reshape the query, key and value such that each head has query dimension, key dimension and value dimension equal to head_dimension.
query = query.reshape(N, query_len, self.heads, self.head_dim)
key = key.reshape(N, key_len, self.heads, self.head_dim)
value = value.reshape(N, value_len, self.heads, self.head_dim)
# calculate attention scores QK.T
# Remember: While using einsum, you only need to specify the ranks of input matrices and the output matrix, the internal computation is handled accordingly.
attention_scores = torch.einsum('nqhd, nkhd-> nhqk', [query, key])
# the input sentences are of same length even if some sentences have fewer words.
# Suppose Sentence 1 has 5 words and Sentence 2 has 11 words.
# Padding is done in sentence 1 with 6 tokens so that sentence 1 and sentence 2 has same length
# In reality, the padded 6 tokens in sentence 1 are meaningless so we require a mask to tell which tokens are real and which are not.
# Hence for sentence 1 the mask will be [1,1,1,1,1,0,0,0,0,0,0]
# For sentence 2, the mask will be [1,1,1,1,1,1,1,1,1,1,1]
# Final mask = [[1,1,1,1,1,0,0,0,0,0,0],
# [1,1,1,1,1,1,1,1,1,1,1]]
# As the non-real tokens add no value to sentence, computing attention scores on these non-real tokens is of no use.
# Hence we replace the attention scores calculated from these non-real tokens to large negative values.
# On applying softmax to these large negative values, the final attention weight will be zero.
# This satisfies our goal to not have any attention from non-real tokens.
if mask is not None:
attention_scores = attention_scores.masked_fill(mask == 0, -1e-20)
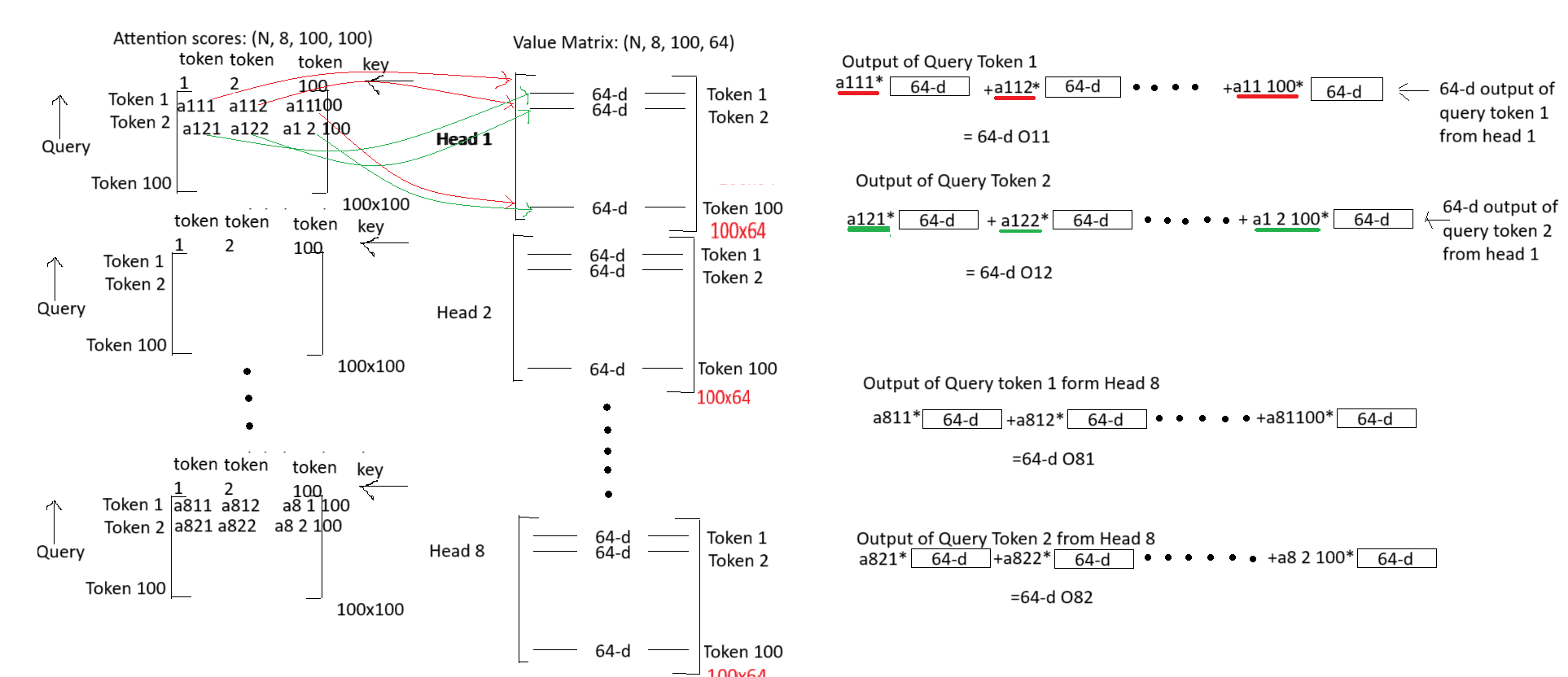
# attention weight = softmax(QK.T/sqrt(dk)) here dk is the dimension of the query which is equal to head dim
attention_weights = torch.softmax((attention_scores)/(self.head_dim ** 0.5), dim = 3)
# dimension of attention_values : (N, heads, query_len, key_len)
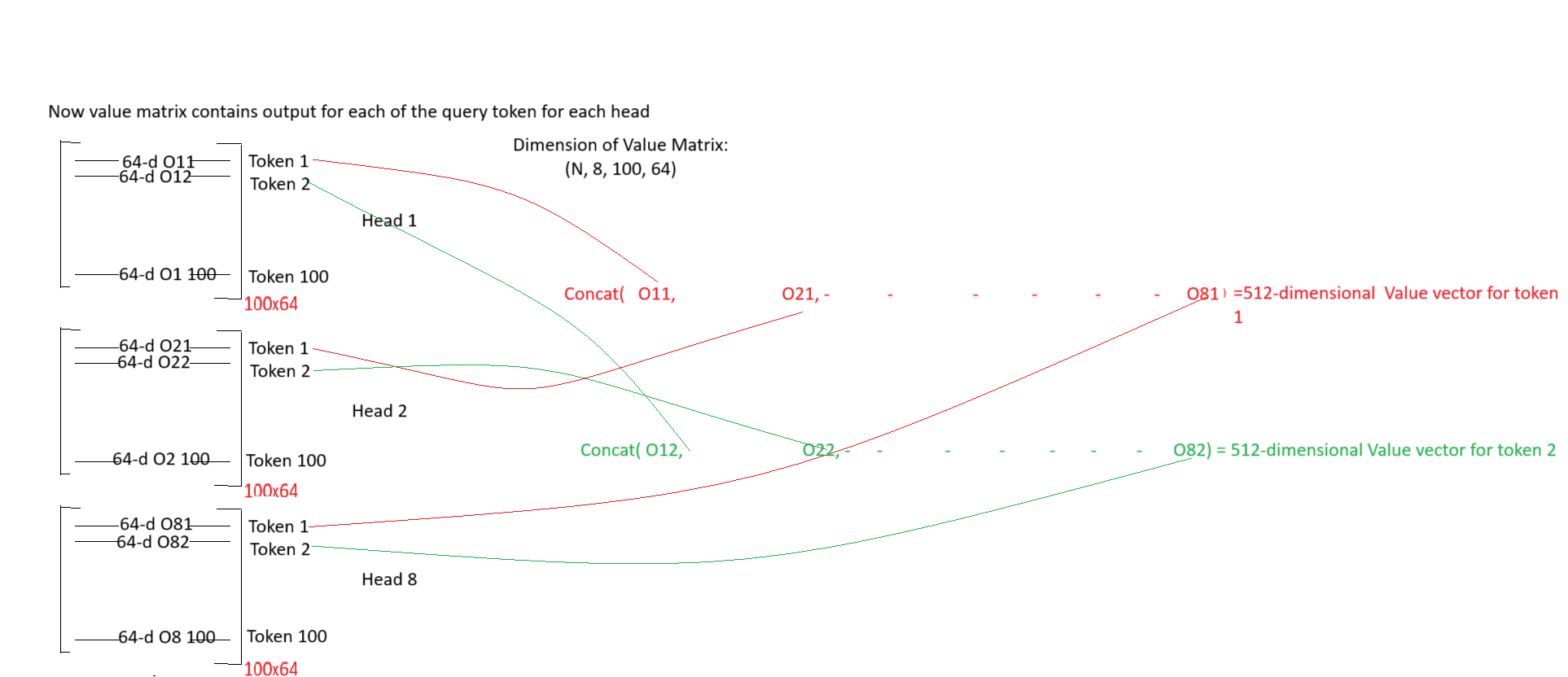
# multiply attention values with value vector then reshaping to concatenate all 64-dimensional value vectors of all heads into 512-d value vector
out = torch.einsum('nhqk, nkhd -> nqhd', [attention_weights, value]).reshape(N, query_len, self.heads*self.head_dim)
# pass the 512-dimensional value vector through the linear layer
out = self.fc(out)
return outNow, lets build the transformer block
![]()
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.fc = nn.Sequential(
nn.Linear(embed_size, embed_size), # here forward expansion is also added in some tutorials
nn.ReLU(),
nn.Linear(embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask):
attention = self.attention(query, key, value, mask)
fc_in = self.dropout(self.norm1(attention + query))
fc_out = self.fc(fc_in)
out = self.norm2(fc_out + fc_in)
return outAfter building the transformer block, we build the encoder block that contains transformer block and the positional encodings and input embeddings.
![]()
class Encoder(nn.Module):
def __init__(self, num_embeddings, max_len, embed_size, heads, num_layers, dropout):
super(Encoder, self).__init__()
self.embedding_layer = nn.Embedding(num_embeddings, embed_size)
self.positional_encoding = nn.Embedding(max_len, embed_size)
self.transformer_layers = nn.ModuleList(
[TransformerBlock(embed_size, heads, dropout) for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, input, mask):
N, seq_len = input.shape
input_position = torch.arange(0, seq_len).expand(N, seq_len) # for every input, we store the position of the input words
# in the input sentence
input_embedding = self.embedding_layer(input)
positional_embedding = self.positional_encoding(input_position)
combined_input = input_embedding + positional_embedding
out = self.dropout(combined_input)
for transformerBlock in self.transformer_layers:
out = transformerBlock(out, out, out, mask)
return outEmbedding layer takes two important parameters: - the vocab size - the dimension of each token in the vocabulary.
How embedding layer encodes vector representation of the tokens.
Suppose the vocabulary includes 5 words [‘I’, ‘am’, ‘go’ , ‘to’, ‘school’]
and we want the vector representation of each word of 10 dimension. The Embedding Layer is initialized as follows:
embedding_layer = nn.Embedding(num_embeddings = 5, embedding_dim = 10)
Now, if we want the vector representation of the sentence ‘I go to school’, we represent the sentence with token indices [1,3,4,5]
embedding_layer([1,3,4,5]) will give the 10 dimensional vector representation of each of the tokens in the sentence ‘I go to school’.
How embedding layer encodes vector representation of the position of the tokens in the sentence.
In the above sentence ‘I go to school’, token ‘I’ appears at position 0 in the sentence, token ‘go’ appears at position 1 in the sentence.
Initally, the position of the tokens is [0,1,2,3].
The embedding layer takes [0,1,2,3] as input and then the weights learnt tell at what position token ‘I’ should appear in any new sentence.
The model learns that certain words tend to appear in certain positions, not because we tell it where they should appear, but because it observes this from training data using the combination of token + positional embeddings.
Lets build the decoder block
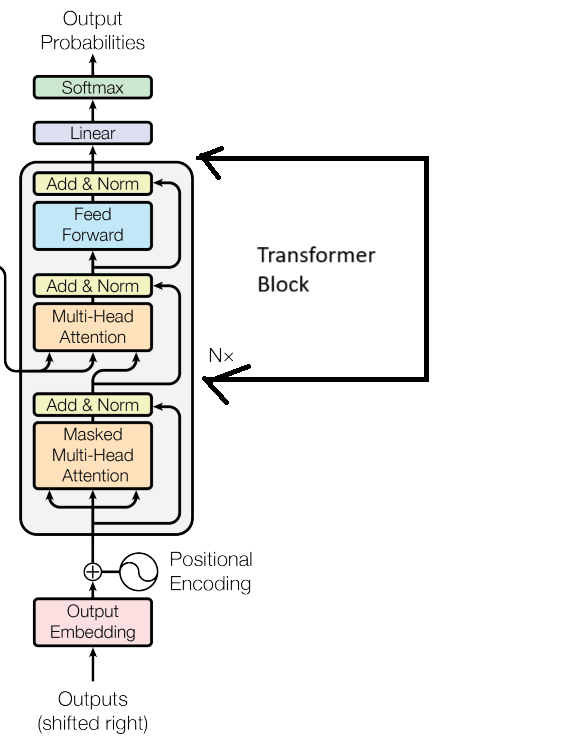
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, dropout):
super(DecoderBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.transformer_block = TransformerBlock(embed_size, heads, dropout)
self.norm = nn.LayerNorm(embed_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, key, value, source_mask, target_mask):
x = self.attention(input, input, input, target_mask)
query = self.dropout(self.norm(x + input))
out = self.transformer_block(query, key, value, source_mask) # Here the query is coming from the decoder attention module
return out
class Decoder(nn.Module):
def __init__(self, target_vocab_size, max_len, embed_size, heads, num_layers, dropout):
super(Decoder, self).__init__()
self.embedding_layer = nn.Embedding(num_embeddings=target_vocab_size, embedding_dim= embed_size)
self.positional_embedding = nn.Embedding(num_embeddings= max_len, embedding_dim= embed_size)
self.decoder_layers = nn.ModuleList([
DecoderBlock(embed_size, heads, dropout) for _ in range(num_layers)
])
self.fc = nn.Linear(embed_size, target_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, enc_out, source_mask, target_mask):
N, seq_len = input.shape
positions = torch.arange(0, seq_len).expand((N, seq_len))
x = self.dropout(self.embedding_layer(input) + self.positional_embedding(positions))
for decoder_layer in self.decoder_layers:
x = decoder_layer(x, enc_out, enc_out, source_mask, target_mask)
out = self.fc(x) # why no softmax operation is done after Linear layer?
return out
Integrate all the blocks to get the transformer
![]()
Masking is very important in case of Self Attention in decoder. It ensures that future tokens are not seen.
Decoder generates the tokens one at a timestep (autoregressive token generation).
During training, the target sentence is available at all timesteps. Here masking ensures tokens of timestep > t are not seen at timestep t.
During infernce, masking is not required because tokens of timestep t+1 are not poduced by the time token at timestep t is generated.
Suppose our task is language translation from English to Hindi.
Source sentence: I am going to school Target sentence: Mai school jaa raha hu.
Token in target sentence: [‘Mai’, ‘school’,‘jaa’, ‘raha’, ‘hu’]
All the token in the target sentence is the input to the decoder but it will be right shifted.
Decoder input: [‘
Query, Key and Value are computed from the decoder input
Attention scores are computed between Query and the Key
attn_score = torch.randn((5,5))
attn_score
tensor([[1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0.],
[1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1.]])
mask = torch.tril(torch.ones((5,5)))
mask
tensor([[1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0.],
[1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1.]])
attn_score = attn_score.masked_fill(mask == 0, -1e20)
attn_weight = torch.tril(attn_score) #Here softmax is applied
attn_weight
tensor([[-0.3627, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.3311, -0.5411, 0.0000, 0.0000, 0.0000],
[-0.6262, -0.9632, -0.4826, 0.0000, 0.0000],
[ 1.2154, -0.2964, 0.2686, 0.8283, 0.0000],
[-0.7835, 0.8071, 0.9509, 0.3160, 0.4949]])Each row in attn_weight represents one timestep.
class Transformer(nn.Module):
def __init__(self, src_pad_idx, source_vocab_size, target_vocab_size, max_len, embed_size, heads, num_layers, dropout):
super(Transformer, self).__init__()
self.src_pad_idx = src_pad_idx
self.encoder = Encoder(source_vocab_size, max_len, embed_size, heads, num_layers, dropout)
self.decoder = Decoder(target_vocab_size, max_len, embed_size, heads, num_layers, dropout)
def create_source_mask(self, source_input):
mask = (source_input != self.src_pad_idx)
mask = mask.unsqueeze(1).unsqueeze(2) # (num_of_sentences, num_of_attention_heads, num_of tokens_in_query, num_of_tokens_in_key)
def create_target_mask(self, target_input):
N, seq_len = target_input.shape
mask = torch.tril(torch.ones((N, 1, seq_len, seq_len))) # (num_of_sentences, num_of_attention_heads, num_of_token_in_target_sentence, num_of_token_in_target_sentence)
return mask
def forward(self, source_input, target_input):
source_mask = self.create_source_mask(source_input)
target_mask = self.create_target_mask(target_input)
enc_out = self.encoder(source_input, source_mask)
out = self.decoder(target_input, enc_out, source_mask, target_mask)
return outsrc_pad_idx = 0
source_vocab_size = 8
target_vocab_size = 8
max_len = 10
embed_size = 512
heads = 8
num_layers = 6
dropout = 0.2
source_input = torch.tensor([[1,2,3,4,5,6,7,2,0,0],
[2,4,5,6,7,1,5,3,4,0]])
target_input = torch.tensor([[1,2,3,4,5,6,7,1,0,0],
[2,4,5,6,7,1,2,3,4,0]])
model = Transformer(src_pad_idx, source_vocab_size, target_vocab_size, max_len, embed_size, heads, num_layers, dropout)
out = model(source_input, target_input[:, :-1])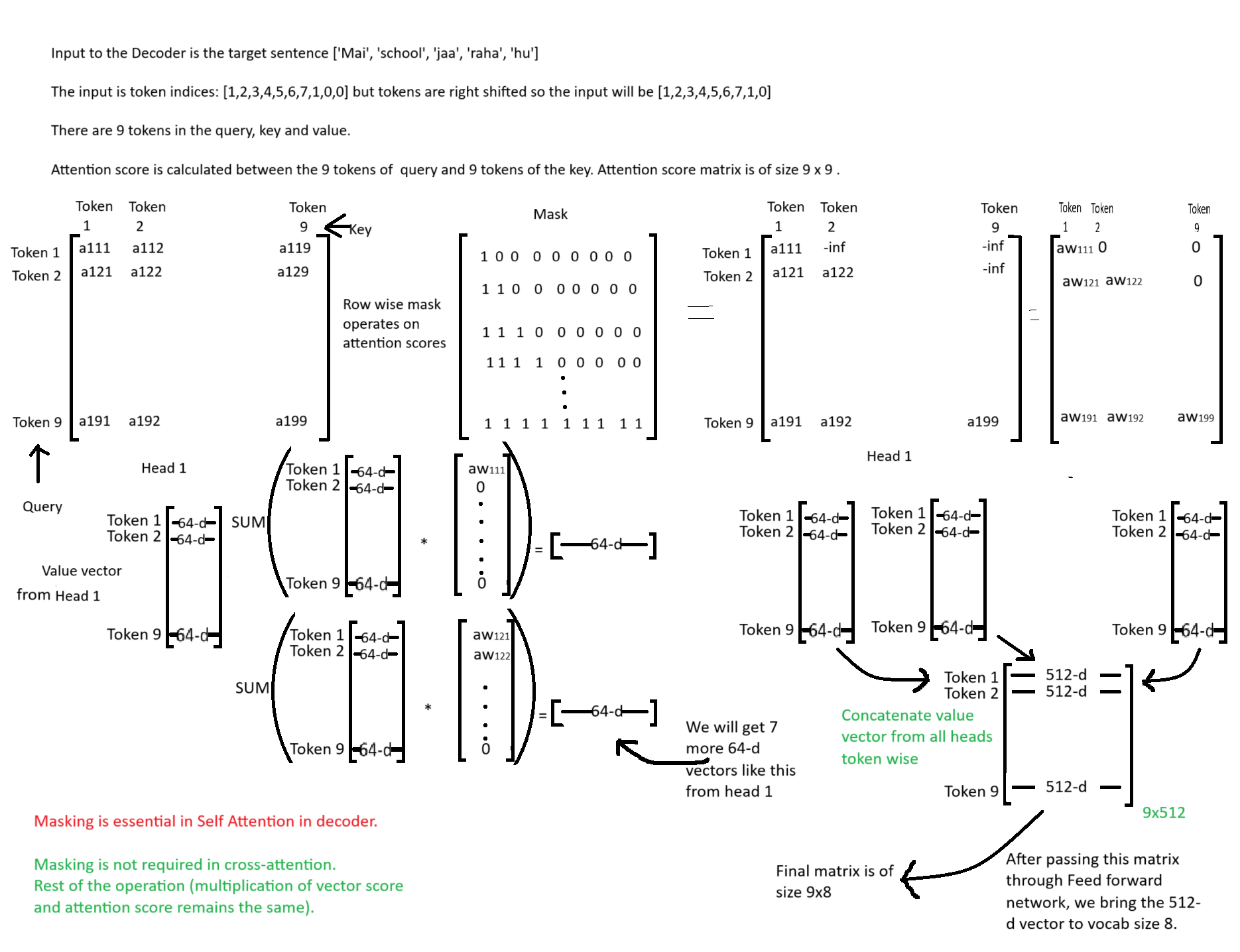
out.shapetorch.Size([2, 9, 8])outtensor([[[-2.4522e-01, 7.5161e-01, 1.5044e-01, -4.4457e-01, -3.6331e-01,
-1.3185e-01, -4.4139e-01, 1.1206e+00],
[-2.5892e-01, 1.8479e-01, -2.6550e-01, 1.3232e-02, 1.1513e+00,
6.2616e-01, -4.4417e-01, -4.3183e-02],
[-1.2515e-01, -5.5137e-01, -2.0334e-01, -7.0015e-01, 2.9892e-01,
-6.1758e-01, -3.9991e-01, -4.0937e-01],
[-9.3089e-01, 5.5678e-02, 4.7316e-01, 2.9314e-01, -3.2622e-01,
2.1052e-01, -5.2436e-02, 1.0685e+00],
[ 4.6724e-01, -1.6304e-01, -8.9153e-01, 1.1432e-03, -2.7380e-02,
7.6934e-01, -2.4154e-01, 6.7970e-01],
[-1.0680e-01, 7.6220e-01, 2.3358e-01, -8.6498e-01, 3.1073e-01,
-6.9051e-01, -2.1195e-01, -4.0020e-02],
[ 1.1692e-01, -8.2362e-01, -5.6247e-01, -1.5735e+00, -8.2848e-01,
-6.7880e-02, 5.4737e-02, 3.4298e-01],
[-7.3295e-01, 2.4218e-01, 5.4857e-01, -5.2408e-01, 1.7051e-01,
-5.0285e-01, 3.9243e-02, 1.5502e-01],
[ 3.7826e-01, 2.6755e-02, 5.0969e-01, 9.6464e-01, -1.7561e-01,
-4.5683e-03, 1.6245e-02, -2.0068e-01]],
[[-4.4446e-01, 2.6719e-01, -7.4989e-02, 5.0081e-02, 4.7049e-01,
-1.9041e+00, 5.1257e-01, 3.2910e-01],
[-1.5257e-01, -4.6883e-01, 8.6818e-01, 2.2030e-02, 2.9119e-01,
9.4907e-01, 5.7688e-01, -1.4505e-01],
[-6.3640e-01, -7.2573e-01, -6.0644e-01, -2.1226e-01, 1.5071e-02,
4.0294e-01, 3.7317e-01, -7.1153e-01],
[-1.6581e-02, 1.0416e+00, 9.1748e-01, 1.4845e-01, 1.3690e+00,
3.0138e-01, 3.2478e-01, 2.8285e-01],
[ 8.3124e-01, 2.7311e-01, 1.6623e-01, -4.6480e-01, 7.8047e-02,
-4.7173e-01, 2.1744e-01, 1.8619e-01],
[-1.4566e-01, 3.1397e-01, -1.5519e-01, -1.1649e+00, 5.8320e-01,
-6.6345e-01, -3.9948e-02, -9.0548e-01],
[ 1.7868e-01, 4.2507e-01, 2.1227e-01, -2.4670e-02, 1.2108e+00,
1.0988e-02, 1.4864e-01, 2.1023e-01],
[ 4.6141e-01, 4.7899e-01, 8.3111e-01, -6.7718e-01, -1.2969e-01,
-6.5497e-01, 1.2411e+00, -8.8316e-01],
[-7.8651e-01, 4.2094e-01, 2.6151e-02, -3.9575e-03, 6.4821e-01,
2.4018e-01, -1.1315e-01, 1.1400e-01]]], grad_fn=<ViewBackward0>)References:
- https://github.com/aladdinpersson/Machine-Learning-Collection/blob/master/ML/Pytorch/more_advanced/transformer_from_scratch/transformer_from_scratch.py
Einsum usage
A = torch.arange(1, 17)
B = torch.arange(100,116)
A = A.reshape((4,4))
B = B.reshape((4,4))
torch.einsum('ij,kj->ik', A,B)tensor([[1080, 1090, 1100, 1110],
[2776, 2802, 2828, 2854],
[4472, 4514, 4556, 4598],
[6168, 6226, 6284, 6342]])torch.einsum('ij,jk', A,B)tensor([[1080, 1090, 1100, 1110],
[2776, 2802, 2828, 2854],
[4472, 4514, 4556, 4598],
[6168, 6226, 6284, 6342]])torch.einsum('ij,jk->ik', A,B)tensor([[1080, 1090, 1100, 1110],
[2776, 2802, 2828, 2854],
[4472, 4514, 4556, 4598],
[6168, 6226, 6284, 6342]])A@Btensor([[1080, 1090, 1100, 1110],
[2776, 2802, 2828, 2854],
[4472, 4514, 4556, 4598],
[6168, 6226, 6284, 6342]])torch.einsum('ij,kj->ikj', A, B)tensor([[[ 100, 202, 306, 412],
[ 104, 210, 318, 428],
[ 108, 218, 330, 444],
[ 112, 226, 342, 460]],
[[ 500, 606, 714, 824],
[ 520, 630, 742, 856],
[ 540, 654, 770, 888],
[ 560, 678, 798, 920]],
[[ 900, 1010, 1122, 1236],
[ 936, 1050, 1166, 1284],
[ 972, 1090, 1210, 1332],
[1008, 1130, 1254, 1380]],
[[1300, 1414, 1530, 1648],
[1352, 1470, 1590, 1712],
[1404, 1526, 1650, 1776],
[1456, 1582, 1710, 1840]]])torch.einsum('ij,kl->ijkl', A, B)tensor([[[[ 100, 101, 102, 103],
[ 104, 105, 106, 107],
[ 108, 109, 110, 111],
[ 112, 113, 114, 115]],
[[ 200, 202, 204, 206],
[ 208, 210, 212, 214],
[ 216, 218, 220, 222],
[ 224, 226, 228, 230]],
[[ 300, 303, 306, 309],
[ 312, 315, 318, 321],
[ 324, 327, 330, 333],
[ 336, 339, 342, 345]],
[[ 400, 404, 408, 412],
[ 416, 420, 424, 428],
[ 432, 436, 440, 444],
[ 448, 452, 456, 460]]],
[[[ 500, 505, 510, 515],
[ 520, 525, 530, 535],
[ 540, 545, 550, 555],
[ 560, 565, 570, 575]],
[[ 600, 606, 612, 618],
[ 624, 630, 636, 642],
[ 648, 654, 660, 666],
[ 672, 678, 684, 690]],
[[ 700, 707, 714, 721],
[ 728, 735, 742, 749],
[ 756, 763, 770, 777],
[ 784, 791, 798, 805]],
[[ 800, 808, 816, 824],
[ 832, 840, 848, 856],
[ 864, 872, 880, 888],
[ 896, 904, 912, 920]]],
[[[ 900, 909, 918, 927],
[ 936, 945, 954, 963],
[ 972, 981, 990, 999],
[1008, 1017, 1026, 1035]],
[[1000, 1010, 1020, 1030],
[1040, 1050, 1060, 1070],
[1080, 1090, 1100, 1110],
[1120, 1130, 1140, 1150]],
[[1100, 1111, 1122, 1133],
[1144, 1155, 1166, 1177],
[1188, 1199, 1210, 1221],
[1232, 1243, 1254, 1265]],
[[1200, 1212, 1224, 1236],
[1248, 1260, 1272, 1284],
[1296, 1308, 1320, 1332],
[1344, 1356, 1368, 1380]]],
[[[1300, 1313, 1326, 1339],
[1352, 1365, 1378, 1391],
[1404, 1417, 1430, 1443],
[1456, 1469, 1482, 1495]],
[[1400, 1414, 1428, 1442],
[1456, 1470, 1484, 1498],
[1512, 1526, 1540, 1554],
[1568, 1582, 1596, 1610]],
[[1500, 1515, 1530, 1545],
[1560, 1575, 1590, 1605],
[1620, 1635, 1650, 1665],
[1680, 1695, 1710, 1725]],
[[1600, 1616, 1632, 1648],
[1664, 1680, 1696, 1712],
[1728, 1744, 1760, 1776],
[1792, 1808, 1824, 1840]]]])